
Anthropic’s RSP v3.0: How it Works, What’s Changed, and Some Reflections
Anthropic’s Responsible Scaling Policy (RSP) – its framework for managing catastrophic risks – has undergone its most significant update yet.
Sophie Williams, Jonas Freund
GovAI research blog posts represent the views of their authors rather than the views of the organization. You can read about GovAI’s governance structure and approach to conflicts of interest here.
Summary
Anthropic’s Responsible Scaling Policy (RSP) – its framework for managing catastrophic risks – has undergone its most significant update yet.
- The old RSP defined capability levels and corresponding safety and security mitigations that would be required to keep risk at an acceptable level. Anthropic made a commitment to pause the development and deployment process if it couldn’t implement the required mitigations before reaching the next level.
- Anthropic now argues that some commitments in the old RSP only make sense if they’re matched by other companies. Otherwise, Anthropic might fall behind, which would be bad from a safety perspective, according to the company.
- That’s why some mitigations – such as RAND Security Level 4 – are now framed as “industry-wide recommendations”. Anthropic also dropped its pause commitment. But importantly, Anthropic is not lowering any of its existing mitigations.
- To compensate for the changes, the new RSP v3.0 introduces Risk Reports – which go beyond current system cards by providing an overall risk assessment – and a Frontier Safety Roadmap – which is a detailed list of non-binding safety goals. It also commits to matching competitors’ mitigations if they’re more effective and can be implemented at similar cost.
- Our initial reaction to the update was rather negative. We were particularly concerned about the pause commitment being dropped, mainly because it makes it more likely Anthropic will deploy models that pose unacceptable risks. However, after engaging with it more closely, our overall view became more positive. In particular, we think the Roadmap and Risk Reports are valuable for increasing transparency, though they still largely rely on self-reporting.
- The update will likely affect what other companies do next. We hope they will also adopt Risk Reports and Roadmaps. At the same time, we’re concerned that others will use the update as an excuse to weaken their commitments without adequate countermeasures.
- On balance, we think it’s better to be honest about constraints than to keep commitments that won’t be followed in practice. Whether or not the update will be net positive depends on how Anthropic will implement these changes and how other companies react.
Background
Anthropic published the initial version of the Responsible Scaling Policy (RSP) in September 2023. The RSP describes how Anthropic intends to assess and mitigate potentially catastrophic risks from its models. Anthropic was the first company to publish this kind of frontier AI safety framework. Since then, 11 other companies have adopted similar frameworks. These frameworks have even served as a foundation for frontier AI regulation globally, including California’s SB-53, New York’s RAISE Act, and the EU AI Act.1 2
The initial version of the RSP defined capability levels and corresponding risk mitigations that would be required to keep catastrophic risk at an acceptable level. The RSP called the required mitigations “AI Safety Levels” or “ASLs” for short. Anthropic committed to pause the development and deployment process if it couldn’t implement adequate mitigations before reaching the next level. The initial RSP also included a number of procedural commitments (e.g. to appoint a Responsible Scaling Officer, and to regularly update the RSP). These elements were also included in subsequent versions of the RSP, namely v2.0, v2.1, and v2.2.
On 24 February 2026, Anthropic released a substantially updated v3.0 of its RSP. The company’s main justification for the update is a collective action problem: the level of catastrophic risk from AI depends on the actions of all frontier developers. Anthropic argues that it would fall behind if it slowed down to implement mitigations while others failed to do so. In this scenario, less responsible actors could take the lead. In the RSP, Anthropic claims that this would be bad from a safety perspective, because it would lose its “ability to do safety research and advance the public benefit”. Another justification is that the old RSP created perverse incentives: since reaching higher capability thresholds would trigger very costly mitigations or even a pause, Anthropic was incentivized not to declare them. This could give a misleading picture of the risk. Holden Karnofsky, who led the development of RSP v3.0, elaborates on Anthropic’s reasoning in a detailed blog post.
How the new RSP works
Industry-wide recommendations. The new RSP starts by describing a set of recommended actions that Anthropic thinks would be required across the frontier AI industry to keep catastrophic risks reliably low. This includes a recommendation that, at certain capability thresholds, developers provide a “strong argument” that catastrophic harm won’t become significantly more likely. Anthropic says it will “strive to advance these recommendations” but doesn’t commit to them unilaterally or unconditionally. In the old RSP, Anthropic presented some of these industry-wide recommendations as unilateral commitments.
Unilateral commitments. The new RSP also lists mitigations Anthropic commits to regardless of what its competitors do. For example, it commits to maintain at least ASL-3 protections when reaching its thresholds for chemical and biological weapons. These protections include classifier guards, access controls, and security controls. At the high-stakes sabotage threshold, it will detail its models’ capabilities and monitoring practices. At the automated R&D threshold, it commits to pursue the relevant goals set out in its Frontier Safety Roadmap (more on this below).
Frontier Safety Roadmap. The new RSP introduces a Frontier Safety Roadmap, which is a public list of specific goals Anthropic intends to achieve over the coming months and years. The goals are described as “ambitious but achievable” and cover security, alignment, safeguards, and policy. One example is a goal to launch moonshot R&D projects to achieve unprecedented levels of security. Anthropic says it will provide updates on whether it achieves these goals and that falling short would “reflect poorly” on the company. But it makes it clear that the goals are “no hard commitments”.
Risk Reports. The new RSP also commits to publishing a Risk Report every 3 to 6 months. These reports will cover “all publicly deployed models”, as well as “internally deployed models when [Anthropic] determine[s] that these models could pose significant risks above and beyond those posed by [its] public models”. While there is some overlap with system cards – such as describing threat models, evaluation results, and implemented mitigations – Risk Reports go further by providing an assessment of both overall and marginal risk, as well as the company’s reasoning behind decisions to continue with development and deployment. This provides a mechanism for Anthropic to signal when it views industry-level risk as unacceptably high, even if it decides to proceed. This reporting system differs from the status quo, and Anthropic hopes it will improve public awareness.3
In special cases, Anthropic makes additional oversight commitments. If the decision to move ahead with development and deployment is partly based on a marginal risk assessment, the board of directors and the Long-Term Benefit Trust must approve the report. If a model is “highly capable” (which is a very high bar4) and Anthropic deems that the report has been “significantly redacted”, an independent third party will review it. This review includes an assessment of whether the redactions materially change the report’s conclusions.
Governance. Finally, Anthropic maintains a number of governance commitments. A Responsible Scaling Officer oversees compliance with the RSP. Staff can use an anonymous channel to flag potential violations. A third party reviews whether Anthropic has complied with its main procedural commitments on an annual basis. Unredacted Risk Reports are shared with Anthropic’s “regular-clearance” staff.
What’s changed
Anthropic no longer implies that it will pause if it can’t keep risks below acceptable levels. Anthropic previously described its RSP as “a public commitment not to train or deploy models capable of causing catastrophic harm unless we have implemented safety and security measures that will keep risks below acceptable levels”. This implied that it would pause development and deployment if it believed risks were unacceptably high.5 The new RSP removes this language.6
It no longer specifies escalating ASL tiers. In the old RSP, Anthropic included escalating ASL tiers that specified what mitigations would be required for two levels beyond current capabilities. The new RSP only specifies mitigations for the next capability level. Relatedly, references to “ASL-4 Deployment and Security Standards” – which were reserved for higher tiers – no longer appear, though these standards were never clearly defined. Anthropic says this change reflects its view that specifying mitigations for more advanced future capability levels is “overly rigid”.
It now distinguishes between unilateral commitments and industry-wide recommendations. Under the old RSP, all commitments were framed as unilateral commitments. However, it did also include an “escape clause” in a footnote, which would’ve allowed Anthropic to lower its mitigations if competitors weren’t meeting similar standards.7 This meant that all of its commitments were conditional in principle.
The new RSP makes three changes. First, it introduces some explicitly unilateral commitments, albeit relatively modest ones (e.g. maintaining its ASL-3 protections). Second, it makes the conditional nature of the other mitigations more prominent by reframing them as “industry-wide recommendations”. Third, it changes the baseline for future mitigations. Under the old RSP, Anthropic started from a high level of mitigations and would only lower them if competitors weren’t adopting similar ones. Under the new RSP, Anthropic starts from a lower level and will only adopt stronger ones if other companies do or if Anthropic has a clear lead.
It has weakened future security commitments. Anthropic continues to commit unilaterally to ASL-3 security protections, which are already in place. However, more demanding security standards – RAND Security Level 4, which would protect against model weight theft by state-level adversaries – now only appear in the industry-wide recommendations.8 Karnofsky’s post emphasizes how effortful it was to develop and operationalize the ASL-3 protections under the old RSP and claims that higher security standards – like RAND Security Level 5 – aren’t currently possible.
The automated AI R&D threshold has been redefined. In the old RSP, the next threshold beyond current AI R&D capabilities (AI R&D 4) was defined as a model that could “fully automate the work of an entry-level, remote-only Researcher at Anthropic”. The threshold beyond that (AI R&D 5) was defined as a model with “the ability to cause dramatic acceleration in the rate of effective scaling”. The new RSP replaces these with a single threshold: a model capable of “compress[ing] two years of 2018-2024 AI progress into a single year”, which is how Anthropic previously operationalized AI R&D 5. Under the previous AI R&D 4 threshold, Anthropic committed to developing an “affirmative case” explaining how it had mitigated risks to acceptable levels. It no longer commits to producing such a case, though it includes an industry-wide recommendation to produce a “strong argument” at the AI R&D threshold, and its Risk Reports may include some of this analysis.
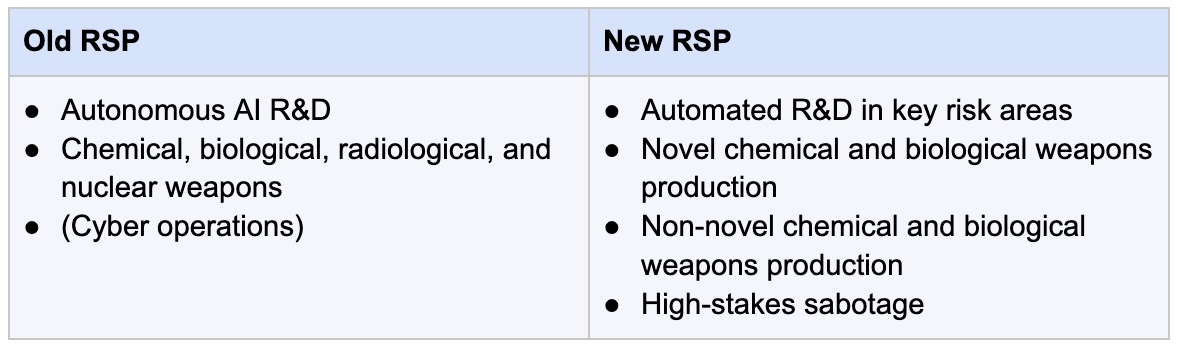
The risk categories have been revised. “High-stakes sabotage” has been added as a new category. This category refers to the risk that a model with extensive access to sensitive assets could manipulate how successor systems are trained or deployed. Chemical and biological risks have been divided into “novel” and “non-novel” weapons. Radiological and nuclear risks have been removed, as have references to cyber operations.9 The new RSP doesn’t give an explanation for their removal, but it may reflect an updated view that these risks are unlikely to result in catastrophic harm.
Reasons to be concerned
Dropping the pause commitment makes it more likely Anthropic will deploy models with unacceptable risks. The pause commitment raised the reputational stakes of deploying a model without adequate mitigations. Doing so would have attracted significant public scrutiny and possibly regulatory intervention. A pause would have been a credible signal that Anthropic thinks the risks are serious and could have galvanized action to address the collective action problem. By contrast, publishing a Risk Report that concludes risk is unacceptably high, while still justifying deployment, will not trigger the same reaction. We’re less concerned about this change than others, partly because we already thought it was unlikely Anthropic would actually pause, and partly because the commitment has always been conditional due to the escape clause.
Some have lost trust in Anthropic’s commitments due to the change. Despite the escape clause, Anthropic gave the impression that its pause commitment was binding. At least that’s how many appear to have interpreted the commitment, and Anthropic failed to correct that impression. Some people have therefore complained that Anthropic made the commitment appear more binding than it actually was. As a result, one might be less confident that Anthropic will follow through with their new commitments. While we understand why people might be skeptical, we largely agree with the justification Anthropic has given for the changes. In particular, we think the collective action problem is real. Whether Anthropic is able to rebuild this trust will depend on whether it follows through on its new policy.
Other companies may lower their commitments in response to the update. Many companies modeled their frameworks on Anthropic’s RSP. If Anthropic says its previous commitments aren’t realistic in the current climate, others may decide to lower theirs – particularly when it comes to pausing deployment. Importantly, Anthropic seeks to offset the changes by introducing additional transparency and accountability measures with its Roadmap and Risk Reports. However, other companies may scale back their commitments in response to the update, without increasing their transparency and accountability in other ways.
If the core problem is collective action, Anthropic should push for stronger regulation, according to its own logic. Karnofsky says that “sufficient regulation isn’t looking likely”. But if Anthropic believes that strong regulation is the only way to address the collective action problem, and existing regulation is insufficient, it should be more proactive in advocating for stronger rules. Although Anthropic appears to be taking some steps along these lines, its efforts seem to lag behind what its own logic suggests, though we recognize that the current political environment presents challenges.
Anthropic could have made more unilateral commitments. Separating unilateral commitments from industry-wide recommendations makes sense. But Anthropic could have included more unilateral and unconditional commitments. For example, it could commit to minimum staffing or investment for the safety goals in its Roadmap. Or it could make additional procedural commitments, such as requiring board sign-off before deploying models above a certain capability level. These would be relatively low-cost but would meaningfully increase accountability.
The new transparency mechanisms still largely rely on self-reporting. Anthropic ultimately sets its own goals, judges its own progress, and decides what to redact. Independent review of Risk Reports is only triggered under narrow conditions. Anthropic argues that broader external review is currently not feasible because there are no well-established organizations for this purpose. But even if that’s true, Anthropic could do more to support the creation of such organizations (e.g. a commitment to work with them would be a credible demand signal). In the meantime, Anthropic will effectively be grading its own homework.
Reasons to be more positive
It’s better to be honest about real-world constraints than to keep commitments that won’t be followed in practice. Put simply, Anthropic had three options. One, it could have kept the pause commitment and actually paused if it couldn’t implement adequate mitigations. But that would mean falling behind other developers and, in the company’s view, losing its ability to do safety research. Two, it could have kept the pause commitment and triggered its escape clause, allowing it to proceed with deployment anyway. But this would create a perverse incentive to argue that the marginal increase in risk was small, even when it wasn’t. Three, it could drop the pause commitment, openly explain its reasoning, and introduce additional measures. Of the three options, number three seems preferable.
More transparency, especially about internally deployed models, is a meaningful step forward. Since AI models can be dangerous before public deployment, we think it’s good that Risk Reports also cover internal models. Similarly, we think it’s good that Risk Reports explain the reasoning behind Anthropic’s decisions to proceed. No other frontier AI company does this in a structured way. The introduction of Risk Reports therefore helps to compensate for the shift away from the pause commitment.
The Roadmap increases confidence that Anthropic is actively working to achieve its industry-wide recommendations. In the old RSP, Anthropic committed to broad standards for more advanced capability tiers (e.g. ASL-4 Deployment and Security Standards), but it didn’t define these or explain how they would be achieved in any detail. Anthropic has since concluded that meeting some of its commitments unilaterally would be prohibitively costly. The Roadmap sets out concrete near-term goals that move the company towards its industry-wide recommendations. This makes it easier to assess how realistic Anthropic’s plans are and the progress it’s making towards them.
Anthropic hasn’t lowered its existing mitigations and makes a general upleveling commitment. Current mitigations – including its ASL-3 protections – remain in place. The update only appears to weaken Anthropic’s commitment to implement stronger mitigations in the future. In addition, Anthropic commits to making a significant effort to match a competitor’s standard if it has strong evidence that the competitor has implemented more effective mitigations, provided this can be done at comparable costs. We think this is a valuable addition because it supports a “race to the top”. We encourage other companies to make similar commitments.
It’s good that Anthropic continues to iterate on the RSP. We don’t think that current safety frameworks will remain fit for purpose. They need to evolve as capabilities and risks increase. The industry shouldn’t settle prematurely on a specific approach. It’s therefore good that Anthropic is willing to challenge the status quo and keeps innovating.
Conclusion
Our initial reaction to the update was rather negative. We were particularly concerned about the pause commitment being dropped. However, after engaging with it more closely, our overall view became more positive. In particular, we think the Roadmap and Risk Reports add significant value and help compensate for the changes. On balance, we think it’s better to be honest about constraints than to keep commitments that won’t be followed in practice.
Acknowledgments
We’re grateful for valuable comments from Aidan Homewood, Alan Chan, Ben Garfinkel, Elias Groll, Luca Righetti, Markus Anderljung, Michael Chen, and Tom Reed (in alphabetical order).
This article was updated on 17 March 2026 to include additional information about Anthropic's commitment to match competitors' mitigations.
Footnotes
1 Relevant provisions in the EU AI Act are concretized by the Safety & Security Chapter of the GPAI Code of Practice.
2 But note that Anthropic recently published a separate Frontier Compliance Framework to meet its statutory obligations.
3 The information in the Risk Reports appears broadly consistent with what companies are expected to provide in quarterly catastrophic risk reports mandated by SB-53 and in “Safety and Security Reports” under the EU GPAI Code of Practice.
4 Anthropic treats a model as “highly capable” if it could “fully automate, or dramatically accelerate, the work of large, top-tier research teams in domains where fast progress could threaten international security or rapidly disrupt the global balance of power”.
5 There’s debate about how strong the pause commitment ever was. While Karnofsky’s blog post acknowledges that the “move away from implied unilateral commitments to ‘pause AI development/deployment as needed to keep risks low’ is the biggest change of RSP v3”, others argue that the commitment was stronger than is now being suggested.
6 This means it’s unclear whether Anthropic would decide to pause if it were unable to meet its unilateral commitments under the new RSP.
7 Anthropic’s original RSP made only a narrow reference to marginal risk defined relative to competitor models. It specified that in an “extreme emergency” – for example, if “a clearly bad actor is scaling in so reckless a manner that it is likely to lead to imminent global catastrophe if not stopped (and where AI itself is helpful in such defense)” – then the company might loosen its own restrictions. The clause was broadened in the second version, which said that if another actor “will pass, or be on track to imminently pass” one of Anthropic’s thresholds without implementing “equivalent” mitigations, then it might lower its own. In such cases, it said it would invest significantly in making a case to the US government for taking regulatory action to mitigate such risk to acceptable levels.
8 This was referred to as the “ASL-4 security standard” in the old RSP.
9 Note that cyber operations were not listed as a formal category in the old RSP, but were identified as a capability under “active assessment”.